Collective View
Online discussion forum
Recognition as an Expert Panel contributor
Synthesis and discussion
- Discussion phaseThis part of the Expert Panel process is an opportunity for panelists to review, debate and revise the synthesis statements, or discuss other topics related to the Panel’s aims.The forum has been seeded with an initial subset of statements reflecting some of the themes emerging from the survey responses. This is intended purely as a starting point for discussion. Panelists are free to add any new threads, comment on proposed statements, suggest revisions and amendments, and generally discuss these issues.This deliberative part of the process should result in a set of considered and debated statements on the main three Expert Panel topics:
- The nature of analytic rigour in intelligence
- Factors impacting on analytic rigour in intelligence
- Opportunities for enhancing analytic rigour in intelligence
At the conclusion of this phase of the Expert Panel process, the Hunt Lab will incorporate the revised set of statements into the final survey, in which panelists will be asked to indicate their level of agreement with each statement. The statements endorsed by a clear majority will constitute the final Collective View. - Expert Panel SynthesisThe Hunt Lab has reviewed and synthesised all responses received as part of the first survey. There were over 50 responses to the survey, generating approximately 700 individual points. There points were synthesised based on similarity and topic into a set of statements within a broader structure.This is a work in progress, and will be revised to reflect discussion that takes place on the online forum during the current (second) week of the Expert Panel processThese statements will form the basis for the final set of statements to be presented to the Panel, which in turn will form the basis of the Collective View. You can read about the process in further detail under “Guidance” below.We have selected a subset of the synthesised statements for initial inclusion in the online forum, and have seeded the forum with these. Panelists will be able to see those as they join the forum, as well as indicated and linked (“Discuss”) in the full list of synthesised statements.See the full set of synthesised statements by clicking below. (You can also see this in a pdf document here).You can also view all responses received in the first survey here. This document precedes the synthesis process and responses are grouped per respondent rather than in reference to theme.
- Forum
For this stage of the process, we are using an online forum called Loomio. Panelists have been emailed with an invitation link to our tailored forum space, and a quick “How To” guide for getting started on the forum.The forum was opened on Tuesday 6 October and will remain open until Tuesday 13 October.Please contact us (hunt-lab@unimelb.edu.au) if you have not received an email or need further assistance with the forum.Resources
We have assembled resources to aid participants in the Expert Panel process.- Analytic Rigour Literature Review Excerpts – Live DocumentThis document comprises a curated selection of some of the most insightful and interesting texts we have identified through our ongoing systematic literature review. We have selected excerpts of interest for the Panel’s review and use, with the purpose of helping to summarise a range of positions and provide grist for the mill. We hope this document can help formulate your answers to our three research questions, and have arranged the excerpts under the question they are most relevant to:
- What is the nature of analytic rigour?
- What are the factors that impact upon it?
- What are the opportunities for enhancing analytic rigour?
The document continues to be updated and enriched as our literature review progresses. You may also add comments or contribute additional sources if you wish by making suggested edits to the document. Click below to access the document.You can also access a pdf version of this document as at 25 September here.So far our review has surfaced approximately 850 works, of which around 280 works remain after applying exclusion criteria. If interested, you can find the full lists in this spreadsheet. - Database of Analytic Rigour LiteratureYou can access our database of analytic rigour literature on the link below. This database aims to be a comprehensive, crowdsourced index of literature related analytic rigour in intelligence analysis. It currently includes approximately 40 choice texts that we identified as having particular insight or relevance to analytic rigour in intelligence through our ongoing systematic literature review. You can contribute additional items by creating an account on the database site.
- Table of Analytic Tradecraft StandardsThis table refers to the following documents: Aid Memoire on Intelligence Analysis Tradecraft, Canadian Forces Intelligence Command (2015), The US Intelligence Community Directive 203 (2007, 2015), the UK Professional Head of Intelligence Assessment (PHIA) Professional Development Framework for all-source intelligence assessment (2019), the US Air Force Handbook 14-33 Intelligence Analysis (2017), and to Daniel Zelik, Emily Patterson and Daniel Wood’s ‘rigor metric’ from “Measuring attributes of rigor in information analysis” (2010).Click the image below to access our table of analytic rigour standards. This draft table is being prepared as part of our in-progress systematic literature review. For further background, see the section entitled “Rating Systems Designed to Evaluate Intelligence Analysis on Tradecraft Standards” below.
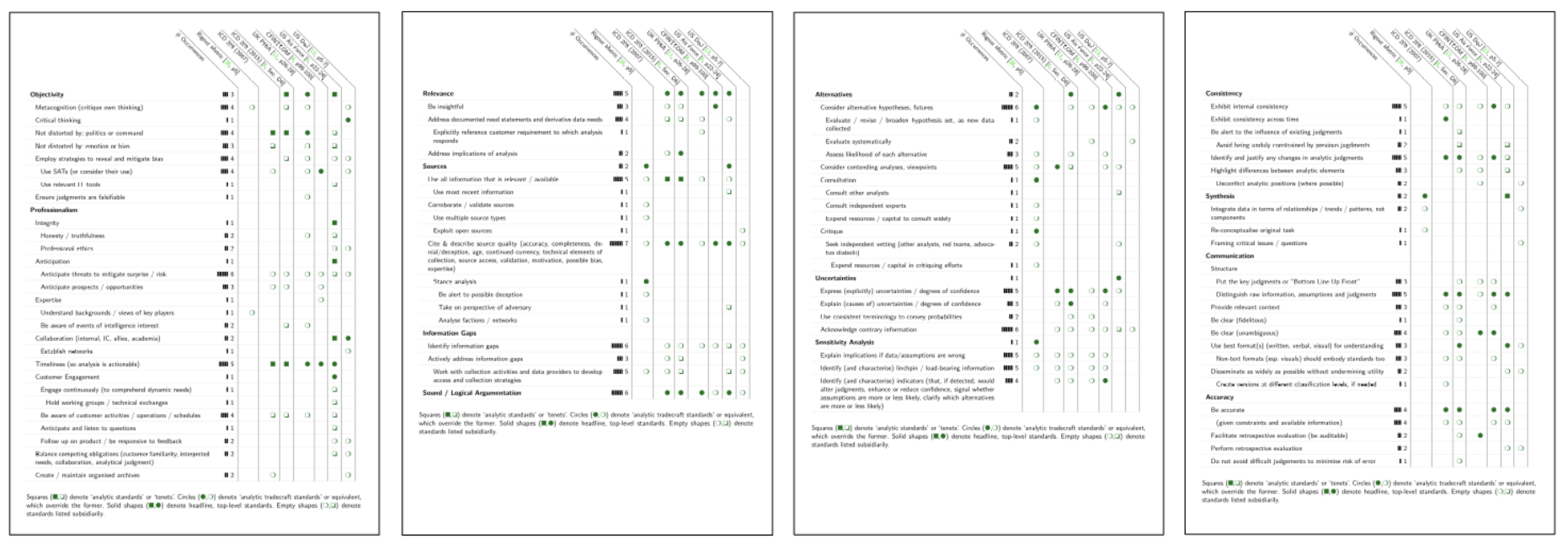
- Rating Systems Designed to Evaluate Intelligence Analysis on Tradecraft StandardsWe are currently aware of four government documents containing clearly identified rubrics or assessment guidelines that should apply to evaluating intelligence analysis and/or products. These documents include US Intelligence Community Directives, including the well-known US Intelligence Community Directive 203 (ICD203), various handbooks and guides for intelligence analysis, professional standards documents, etc. from the UK, Canada, the US, and the UN These documents contain a number attempts to more or less systematically describe the tradecraft standards which intelligence analysts, analysis, and intelligence products, should adhere to and be assessed on.The first of these are the US Intelligence Community Directive (ICD203) and the ODNI Rating Scale for Evaluating Analytic Tradecraft Standards (2015) that developed out of it (and which is accompanied by detailed instructions for the rubric’s use).We are aware of two other rubrics that are based explicitly on the standards outlined in ICD203 and further developed in the ODNI Rating Scale. One of these is a US system contained in the US Air Force Handbook 14-133 Intelligence Analysis (2017), while the other is Canadian, outlined in the Canadian CFINTCOM Aide Memoire (2015), which we are currently seeking permission to share.Notably, both the US Air Force Handbook evaluation criteria and the Canadian Analytic Product Standards introduce additional criteria to their rubrics. The Canadian system introduces two additional criteria, one relating to consistency of analysis over time and another requiring the use of Structured Analytic Techniques (CFINTCOM Aide Memoire, 2015). The Air Force system, on the other hand, introduces a criterion on timeliness, and another regarding customer engagement (Air Force Handbook, 2017, p. 24-25 and 65-68).A third system is the UK Professional Head of Intelligence Assessment’s (PHIA’s) Common Analytic Standards, contained in the PHIA Professional Development Framework. This is not a rating system in itself, but explicitly outlines the standards by which organisations should develop assessment systems and by which intelligence products should be assessed.Additionally, Daniel Zelik, Emily Patterson and David Woods have identified, based on research carried out with participants from the intelligence community, eight key analytic rigour metrics on which analysis can be scored (Zelik et al., 2010).Lastly, a number of other documents in our collection contain discussions of tradecraft standards and professional competencies which may pertain to analytic rigour. While descriptions of competencies are not the same as evaluation systems, some of the criteria/competencies overlap with the standards set by the assessment systems described above. The Core Competencies for State, Local and Tribal Intelligence Analysts (US DOJ, 2010), for example, lists competencies and explicitly links behavioural traits to these competencies.We are currently summarising the main characteristics of these various documents in the table included in the section above (“Table of Analytic Tradecraft Standards”) as part of our ongoing systematic literature review.
Note to readers
We are aware that there are many documents which we have not yet seen that may contain relevant descriptions of tradecraft standards and systems or methods to evaluate intelligence analysis and intelligence products. If you are aware of any unclassified documents that you can share with us, this would be appreciated. We can be contacted at hunt-lab@unimelb.edu.au.
Guidance
- Visual representation of the Panel process
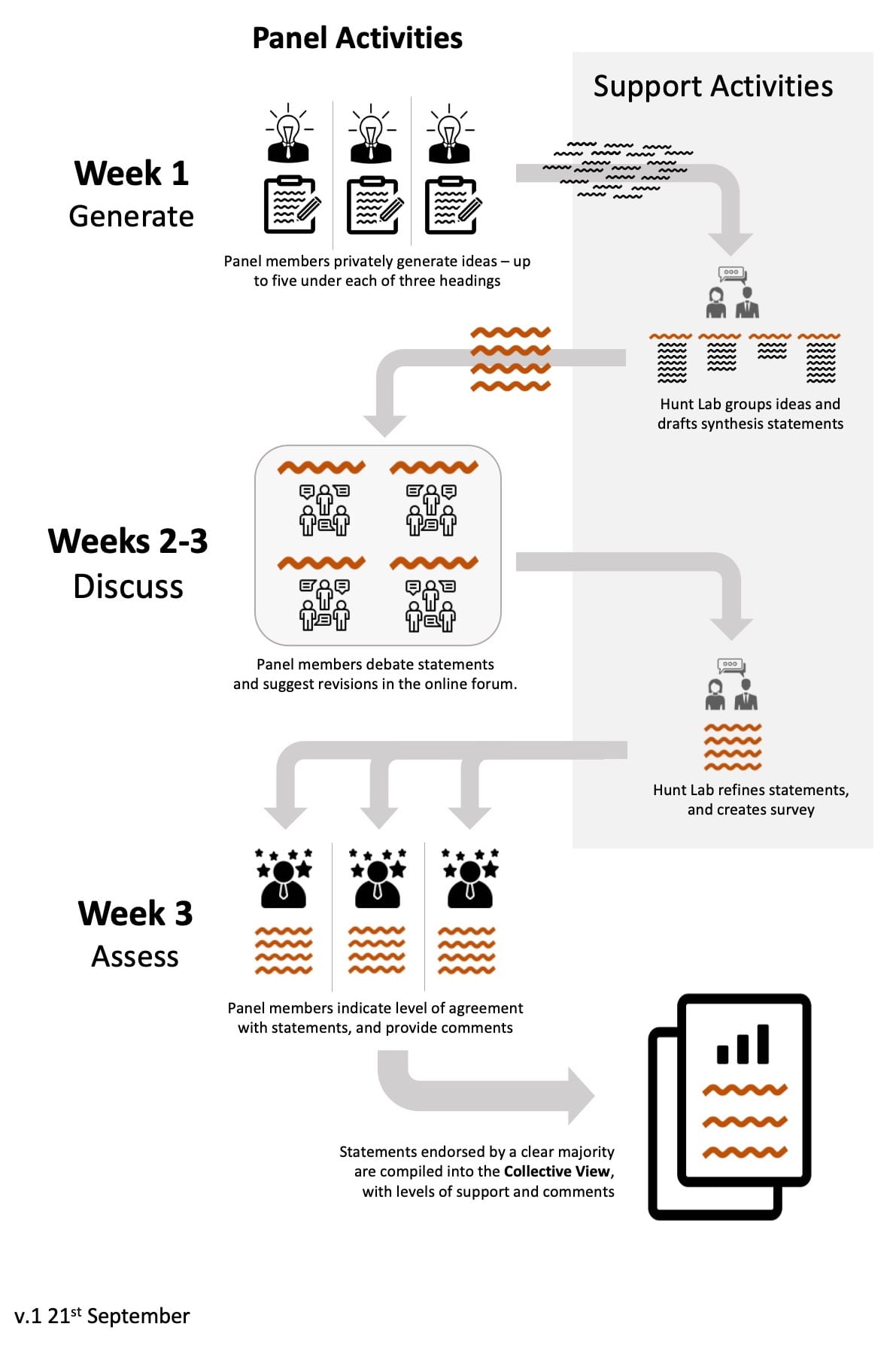 Click here to see the full-sized version of the graphic above.
Click here to see the full-sized version of the graphic above. - Schedule
Panel Activities Support Activities (Hunt Lab) Fri 25th Sep Receive email with resource link Week 1 Mon 28th Generate
Respond to first survey with up to five views under three headings. Survey closes Thursday midnight in your time zoneTue 29th Wed 30th Thu 1st Views and draft statements and prepare forum Fri 2nd Week 2 Mon 5th Discuss
Join the online forum and discuss the statements and other issuesTue 6th Wed 7th Thu 8th Fri 9th Week 3 Mon 12th Tue 13th Redraft statements and prepare second survey Wed 14th Thu 15th Fri 16th Week 4 Mon 19th Assess
Respond to the second survey, assessing all statements and optionally providing comments. Survey closes Monday midnight in your time zoneTues 20th Wed 21st Thu 22nd Fri 23rd Compile and distribute the Collective View document Mon 26th Receive Collective View document in this week. - What is the process trying to achieve?
The process is primarily trying to articulate what the international community of relevant experts collectively thinks about analytic rigour in intelligence, and more specifically what it thinks under the three headings of the nature of rigour, the factors impacting it, and the opportunities for an organisation to enhance it. The relevant experts include academics, intelligence practitioners (analysts or managers, current or retired), and some other government officials.
- What is the output – the Collective View?
The Collective View will be a document containing sets of statements under the three headings listed in the section above. Each statement will have been endorsed by a clear majority of panelists. The level of support (e.g., 69%) will be indicated, and comments made by panelists will be listed beneath it. All ideas suggested by the panelists in the Week 1 survey will be listed in an appendix.
- What exactly is the process?The process has three stages. You can see a visual representation of this under “Visual representation of the Panel process” above.Generate. In the first stage, panelists are surveyed for ideas or views under each of the three headings. The survey is sent to each panelist via email. They are asked to succinctly express up to five views under each heading. These views should be, in the expert’s opinion, the most true and important things that could be said on the topic.The entire set of views expressed by all panelists under a given heading are then sorted into groups based on similarity or “affinity.” The larger groups are the ideas expressed more frequently by the experts. For each of these, a single statement expressing the essence or central tendency is drafted.Discuss. In the second stage, the panelists can debate the statements, propose refinements, or discuss any other relevant matter. This stage is conducted on an online forum.At the end of the discussion period, the statements (both individually and as a set) are revised by the Hunt Lab to reflect the panel’s thinking.Assess. In the third stage, panelists are surveyed for their assessment of each of the revised statements. This survey too is sent to all panelists via email. They are asked whether they agree with the statement, and for any comments.The Collective View is the statements which emerge with support from a clear majority, along with the levels of support and comments associated with each statement.
- The process explained in more detailTo ascertain the Collective View of a group of experts on analytic rigour, we could have tried a simple survey. The problem with this would have been that the results would be heavily influenced by the perspectives and imaginations of those drafting the survey (the Hunt Lab). The experts would respond to the prompts provided by the survey drafters, but these prompts reflect the limited perspectives of the drafters.What we need instead is a process in which the panel itself generates the views to which the panel reacts. To achieve this we are adapting the widely used Delphi method. This method was originally designed as a way to obtain the collective view of an expert group on some numerical forecasting problem. The essence of the method is a series of rounds; in each round the experts privately make their best estimates, which are then shared with the group for discussion. At the end of each round the estimates can be aggregated to form a single group estimate.The challenge in our case is not to forecast some quantity, but to articulate experts’ shared views. These views are qualitative and so can’t be aggregated in any simple statistical manner. What we can try to do is identify the views which find wide agreement among the experts, and quantify that agreement.Thus, our version of the Delphi process starts with the experts privately generating views, akin to the Delphi process of private estimation. These views should be both true and worth saying. We suggest that panelists imagine themselves making a brief presentation on analytic rigour to a senior leader of a major intelligence organisation. If you make up to five points to such a person under each of our headings, what would they be?Previous experience with this kind of process suggests that experts will have diverse perspectives; the views they provide will be quite heterogeneous, and any one view expressed by one or more experts might not be shared by many of the others. Hence we need a process by which the more widely held views are identified, debated and assessed by the group as a whole.To identify the more widely shared views, we sort the experts’ views into groups or “piles” where the views in each group are essentially the same, or very similar. For each of these piles, we draft a statement expressing the core meaning of the views in the pile.These statements form a rough first draft of the Collective View. The first draft will inevitably have lots of problems. The statements might be only poor summaries of the views in their respective piles, and so will need refinement. The piles themselves might need to be reassembled (i.e., the original set of views “sliced and diced” in a different way). Most importantly, however, the statements might be seriously disputed in the expert group. It is possible that the largest piles correspond to views held only by a minority of participants. As such, it is possible that the panel, when asked, will reject the most commonly expressed views.For these reasons, we need the second major phase of our adapted Delphi process, the discussion. Here all statements are made available to all panelists for free-ranging deliberation. Objectives include clarifying whether the statements are true, improving the formulation of the statements, and identifying any gaps, i.e. statements expressing views which appear to be widely held but which happened not to be frequently mentioned in the first survey.On the basis of the discussion, we will produce a revised set of statements. This is the second draft of the Collective View. However, we still will not know to what extent any of these statements are collectively held, i.e. endorsed by the expert panel members. This is why we need the third (“Assess”) stage of the Delphi process.In the third stage, the revised statements are presented to the expert panel in a survey format. For each statement, the experts can indicate whether they agree or disagree, and optionally provide comments.When the survey data is collated, we will get a clear idea of the extent to which the statements are really held by the panel. Those which have clear majority support will make it into the final draft of the Collective View. The level of support for each statement will be included, along with any comments.Note that the Collective View is not a consensus view in the strict sense of a set of positions endorsed by all panel members. The process aims to identify what is broadly or mostly agreed (and the extent to which it is agreed), not what is universally agreed. There might be nothing at all which is universally agreed – or, at least, nothing worth saying.
- Some limitationsOur adapted Delphi process aims to identify the collective view of the expert community under some challenging constraints – a short time frame, experts distributed across many time zones, and face-to-face collaboration precluded by both cost and COVID-19 conditions. The process thus inevitably has some limitations and the Collective View will be only an approximation to the true position of the community. For a realistic assessment of the Collective View, these limitations need to be acknowledged. They include:
- The process design, in which the statements forming the Collective View emerge from the views which happen to be expressed by panelists in the initial survey, might not be a complete representation of the important and widely shared views of the panel. That is, some statements which deserve to be included might not get identified, even after the discussion phase.
- Due to the short time frame for the exercise, the discussion will be quite limited. The Collective View will be closer to what the panelists currently believe than to what they would believe after extensive deliberation.
- The expert panel is not fully representative of the international expert community. It is what is called a “convenience sample.”
Contact
For any further questions, contact us at hunt-lab@unimelb.edu.auWe are able to respond rapidly during business hours, Australian AEST time.The Hunt Laboratory for Intelligence Research
School of BioSciencesThe University of MelbourneParkville VIC 3010 AustraliaDirector: Dr Tim van GelderEmail tgelder@unimelb.edu.au - Forum